tags:
- tuto
- LLM
- local
- gpt4allInstaller une LLM en local pour un humain local
Ce guide s'adresse à un public non spécialisé, qui souhaite prendre en main un modèle de type chatGPT gratuitement sans dépendre des interfaces web OpenAI et des géants de la tech (Google,Microsoft ...) pour des soucis principalement de confidentialité des données.
Le but est de vous faire prendre en main un logiciel open-source utilisant des modèles open-source gratuits, le tout sans aucune compétence technique ni d'ordinateur spécialisé.
Bien évidemment, la puissance de calcul étant un facteur majeur dans la vitesse d'execution du modèle, la taille du modèle doit être modulée selon les capacités.
En fin de page se trouve un lexique pour les différents termes et acronymes utilisés.
Prérequis matériel :
Minimal :
Un ordinateur doté d'au moins 12 Go de RAM
Un processeur de moins de 5 ans
~30 Go de libre sur le disque dur
Recommandé :
Une carte graphique (GPU) NVIDIA de moins de 5 ans et 8 Go de VRAM doté de l'architecture CUDA.
Etape 0 (optionnel) | Avec GPU : installer CUDA Toolkit
Si vous n'avez pas de GPU Nvidia, ignorer cette étape. On peut faire tourner le modèle uniquement sur processeur sans problème.
Sinon,
Installer l'outil CUDA Toolkit pour pouvoir exploiter la GPU avec CUDA en suivant les étapes suivantes :
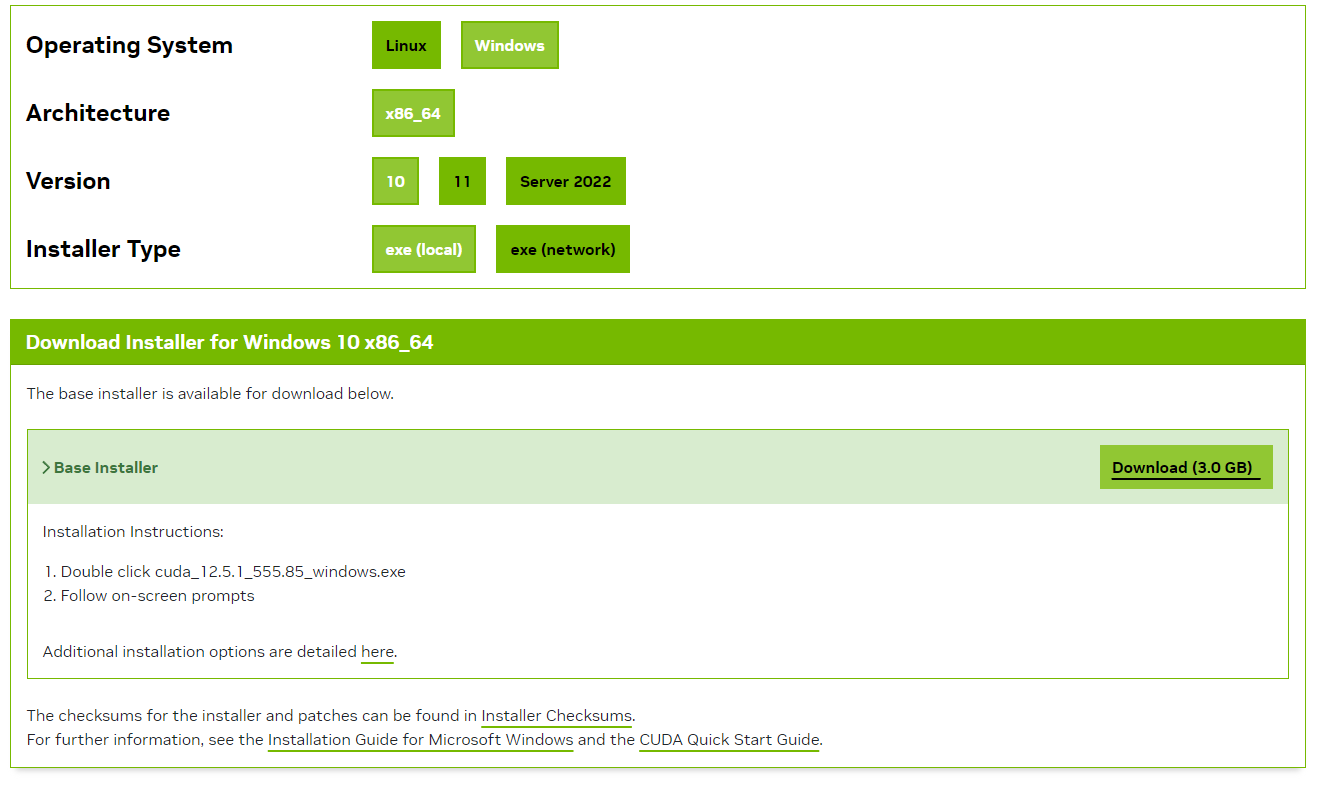
- Suivre les instructions de l'installer .exe après avoir saisi un mot de passe administrateur.
- Cliquer sur suivant jusqu'à cette partie et cocher la case :
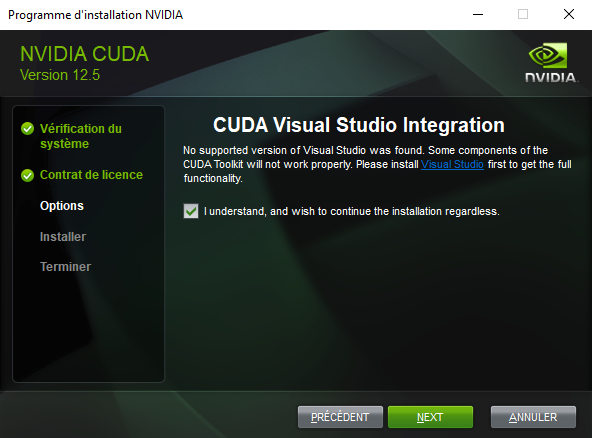
- Suivre les instructions jusqu'à la fin de l'installation.
Voilà, vous pouvez à présent exploiter les capacités de votre carte graphique pour des modèles de deep learning !
Etape 1 : Installer Jan
Télécharger https://jan.ai/ en choisissant votre système d'exploitation (détecté automatiquement par défaut) :
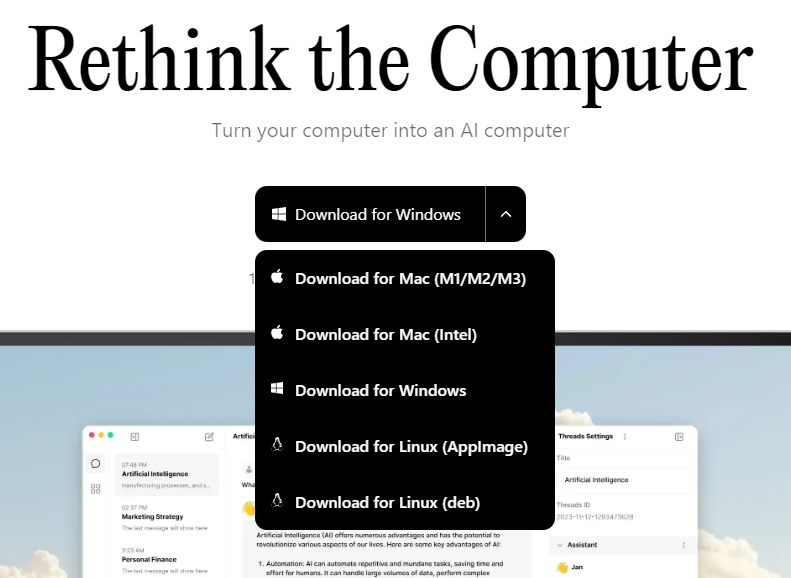
Puis executer l'installer .exe :
Une fois fini, vous arrivez sur la page d'accueil de Jan, avec une plateforme de modèles disponibles à télécharger sur votre machine :
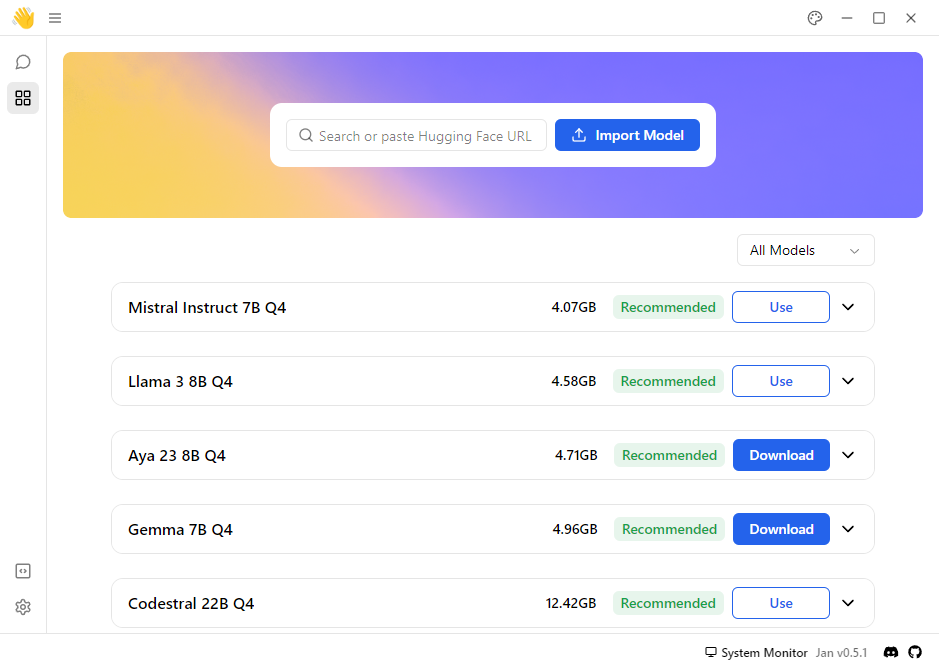
L'application analyse automatiquement les capacités mémoire de votre système pour vous recommander des modèles. Ceux en vert Recommended sont ceux qui peuvent tourner sur votre machine.
Il y a deux types de modèles accessibles ici :
- Les modèles open-source que l'on peut télécharger en local (sur votre machine), par exemple ici Gemma 7B Q4 (modèle Google open-source) qui sont avec le bouton bleu
Download - Les modèles fermés, auquels on peut accéder avec une clé d'API pour intéragir avec comme si on était sur leur site web. Cela nécéssite par contre d'être connecté à internet, contrairement à un modèle local. Les données de chat seront envoyées au fournisseur de modèle également. Par exemple, on peut utiliser une clé d'API OpenAI pour chatter avec chatGPT 4 dans l'interface Jan. Ils sont affichés avec un bouton
Use, sans qu'on les ait installés.
PS: Les modèles dans l'exemple ci-dessus tel que Llama 3 8B Q4 ont le bouton Use parce que je les ai déjà installés sur ma machine.
On peut cliquer sur la flèche pour dérouler la fiche du modèle qui décrit sa spécialité :
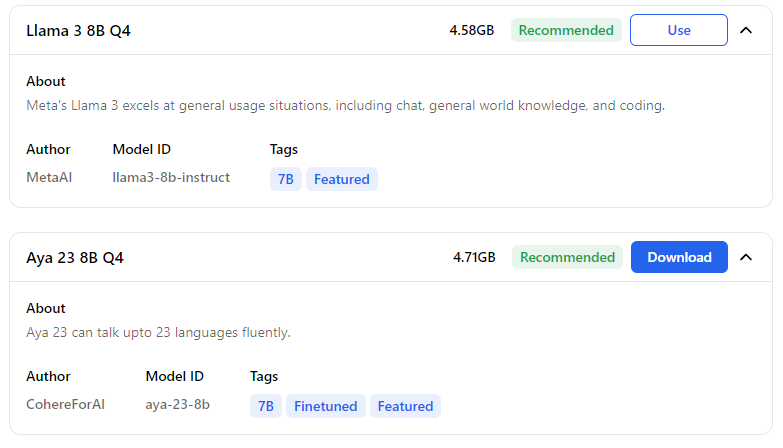
On verra ici que le modèle Aya 23 a été designé et entrainé pour être multilingue, tandis que LLama 3 est un modèle également multilingue mais qui a pour but d'être généraliste et bon codeur.
8B : 8 Billion = 8 milliards de paramètres => Taille en terme de paramètres du modèle.
Q4 : Quantifié sur 4 bits => On a réduit la précision du modèle d'origine avec des paramètres en 32 bits (float32) à 4 bits (INT4) , ce qui le rend 8 fois plus léger. Ce processus s'appelle la Quantization. C'est une des techniques de compression de modèle qui permet de faire tourner des modèles puissants sur des ordinateurs avec une mémoire réduite, avec une faible perte en qualité (varie selon la méthode).
| Model | Original Size (FP16) | Quantized Size (INT4) |
| Llama2-7B | 13.5 GB | 3.9 GB |
| Llama2-13B | 26.1 GB | 7.3 GB |
| Llama2-70B | 138 GB | 40.7 GB |
Une fois un modèle choisi, cliquer sur Download pour lancer le téléchargement. Si une erreur s'affiche, c'est sûrement dû au proxy qui bloque l'accès internet.
Configurer le proxy
Allez sur le bouton paramètres ⚙ en bas à gauche de l'interface et cliquez sur Advanced Settings :
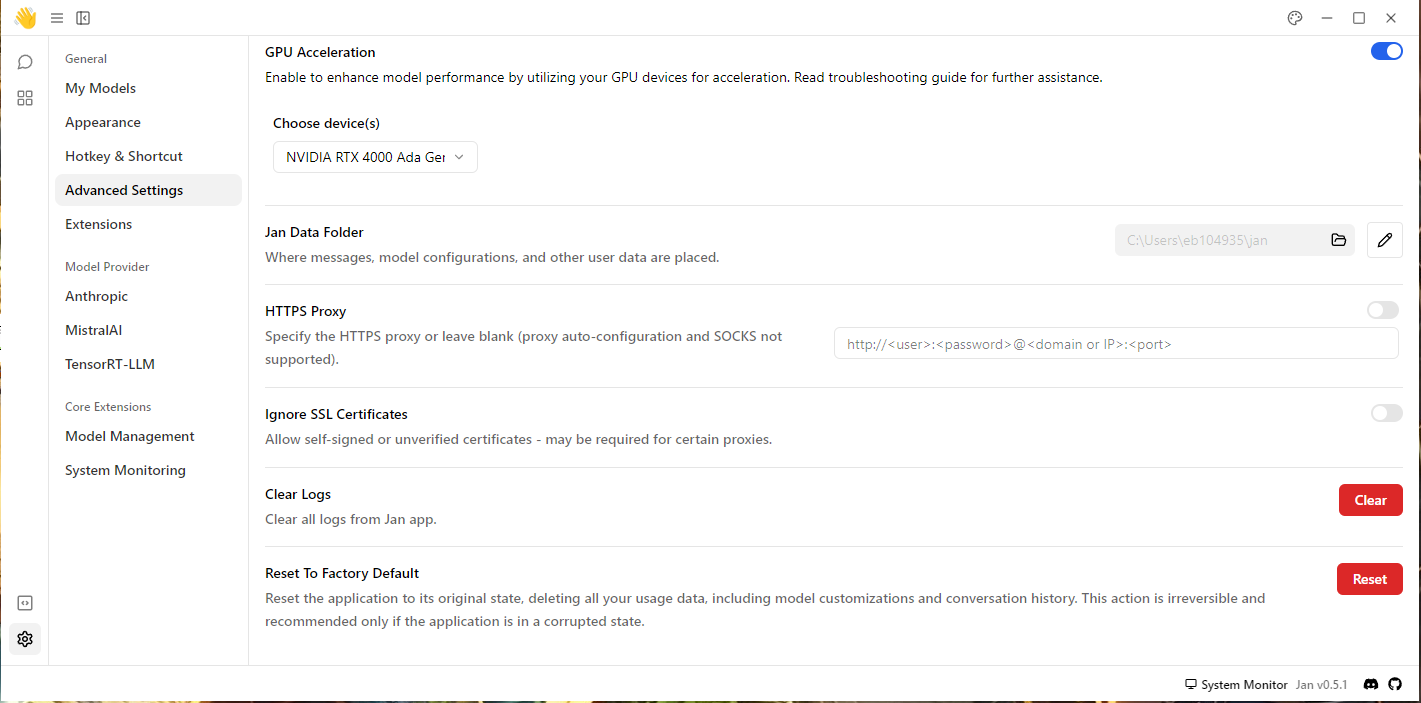
Sur la partie "HTTPS Proxy", saisir l'adresse de votre proxy (ici UJM) :
http://cache.univ-st-etienne.fr:XXXX en remplaçant XXXX par les valeurs de port.
Une fois le proxy configuré, les téléchargements seront possibles !
Configuration recommandée
Sur cette même page, vous pouvez choisir, si vous en avez une, la carte graphique à utiliser sous GPU Acceleration, qu'on doit activer avec le bouton bleu à droite, puis choisir dans le menu déroulant la GPU (ici NVIDIA RTX 4000 ...)
Vous pouvez choisir également où Jan va télécharger les modèles et stocker les conversations dans Jan Data Folder .
Présentation du Chat
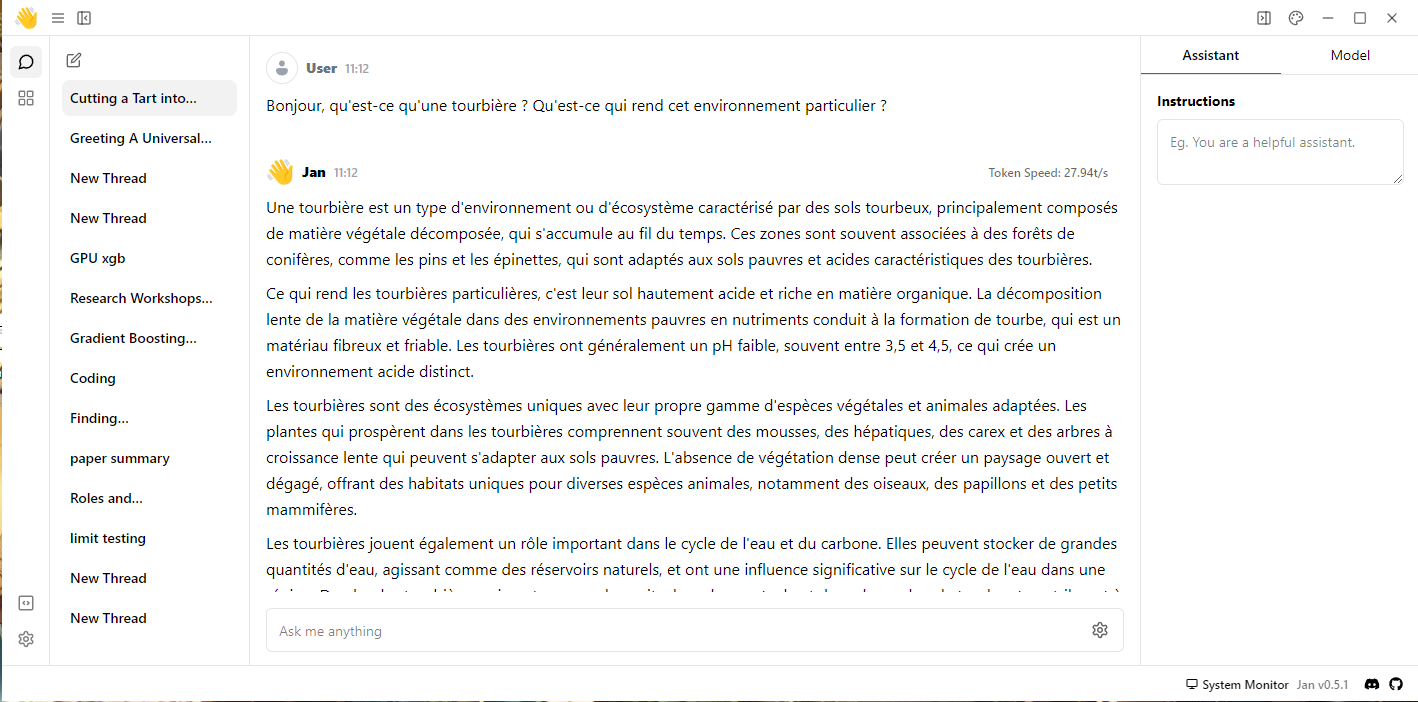
Cette page de Chat s'organise en trois parties principales :
- Sur la gauche, la liste des discussions passées.
- Au centre, la discussion entre l'utilisateur et le modèle de langage.
- Sur la droite, des paramètres d'inférence du modèle.
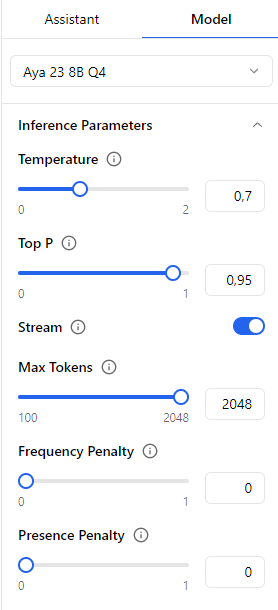
L'onglet Model nous permet de modifier les paramètres de l'inférence du modèle dans Inference Parameters. Chaque paramètre est expliqué en laissant la souris sur l'icone d'information ℹ.
Il y a aussi les paramètres du modèle dans Model Parameters, ainsi que d'autres paramètres dans Engine Parameters :
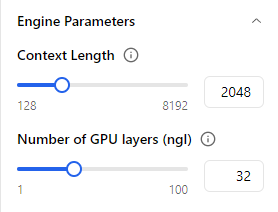
Ces deux paramètres vont largement influencer la performance en terme de rapidité de réponse du modèle, en particulier :
Context Length : nombre de tokens précédents "vus" à l'instant de la génération du prochain token de la phrase.
Plus Context Length est large, plus la quantité de mémoire utilisée est haute et la réponse lente, mais plus elle sera informée de ce qui a été dit précédemment.
🎉 Bravo vous avez fini ce tutoriel ! Vous pouvez maintenant faire tourner n'importe quel modèle open-source adapté à votre machine ! 🎉
Pour continuer sur la suite de ce guide pour faire du Retrieval-Augmented Generation plus avancé mais facile d'utilisation à l'aide de modèles locaux en utilisant GPT4All, suivez le guide RAG simple, local et Open-Source avec GPT4All
Pour une utilisation de LM Studio et DeepSeek : suivre le guide Installer DeepSeek R1 Distill en local
Lexique :
LLM :
Large Language model = Large Modèle de langage (type ChatGPT)
en local :
Installation sur la machine physique et non pas sur un serveur distant (cloud / interface web)
GPU / Carte Graphique :
Graphics Processing Unit = Carte Graphique => unité de calcul dédiée au calcul matriciel, utilisé entre autres pour entraîner et executer des modèles de LLM.
CPU / Processeur :
Processeur, unité de calcul primaire de votre ordinateur, plus lent que le GPU pour faire tourner un LLM mais suffisant pour les petits modèles.
CUDA (Compute Unified Device Architecture) :
plateforme de calcul parallèle développée par NVIDIA qui permet aux programmeurs d'exploiter la puissance de traitement parallèle des GPU. Il fournit un ensemble d'outils et d'API pour tirer parti des capacités de calcul des GPU, accélérant ainsi les tâches informatiques complexes. CUDA permet une utilisation efficace des GPU pour le traitement parallèle, ce qui en fait un outil puissant dans le domaine du calcul haute performance.
API (Application Programming Interface) :
est un ensemble défini de routines, protocoles et outils qui permettent à différentes applications de communiquer et d'interagir entre elles. Il s'agit d'une interface qui définit comment les logiciels doivent interagir pour échanger des données et utiliser les fonctionnalités d'un autre logiciel ou système.
Les API simplifient le développement de logiciels en fournissant un ensemble de règles et d'outils que les développeurs peuvent utiliser pour accéder aux fonctionnalités d'un système ou d'une plateforme.
clé d'API :
Une clé d'API est une séquence unique de lettres et de chiffres utilisée pour identifier et authentifier une application ou un service particulier. Il s'agit d'une corde de caractères qui permet à votre application d'accéder de manière sécurisée à une API (interface de programmation d'application). Les clés API sont souvent utilisées pour vérifier l'identité de votre application et vous permettre d'utiliser les fonctionnalités ou les données fournies par l'API.
tokens/jetons : Dans le contexte de l'apprentissage automatique et du traitement du langage naturel, les jetons font référence à des unités de base utilisées pour représenter du texte ou des données.
Ils peuvent être des mots, des caractères ou même des sous-mots, en fonction de la méthode de jetonisation utilisée.
Les jetons sont utilisés pour créer des représentations numériques du langage, qui peuvent ensuite être utilisées pour entraîner des modèles de langage ou effectuer des tâches telles que la classification de texte ou la génération de langage.